
Enterprise AI Projects Don't Fail at Launch. They Fail in the First Two Weeks of Scoping, Always at the Same Point.
AGT
Quick Answer: Enterprise AI projects fail during the first two weeks of scoping, not during the build or deployment. Three decisions made or skipped in that window determine whether a project reaches production. The failure is set in motion before a single line of code is written: outcome is defined as direction instead of a number, data readiness is assumed instead of validated, and the deployment environment is treated as a later problem instead of the first constraint.
MIT's Project NANDA recently found a 75% drop-off between generative AI pilot and production. Gartner puts the broader figure at 85% of enterprise AI projects that never make it to production. McKinsey estimates the average failed AI project costs $960,000 before cancellation. Every major report agrees on the number. Almost none of them agree on the when. The conventional answer is that AI projects fail because of poor data quality, unclear ROI expectations, or lack of organisational buy-in. Those are true. They are also descriptions of symptoms that appeared months before anyone noticed them, symptoms that trace back to a window of 10 to 14 days at the start of every engagement. The failure is not in the model. It is not in the engineering. It is in three decisions that happen, or don't happen, in the first two weeks of scoping. And it looks identical every time, whether the project is in fintech, logistics, cybersecurity, or enterprise operations.

The Window Nobody Is Watching: Days 1 to 14
There is a specific moment in almost every failed AI project where the outcome becomes unfixable. It is not when the demo fails. It is not when the board reviews the results in month nine. It is in the first two weeks, when three things get defined or deferred.
The projects that reach production make these three decisions with precision in week one. The projects that stall, drift, and eventually get cancelled skip all three, usually because the timeline pressure is highest at the start and these decisions feel like they can wait. They cannot wait. By the time you realise they were skipped, you are already rebuilding.
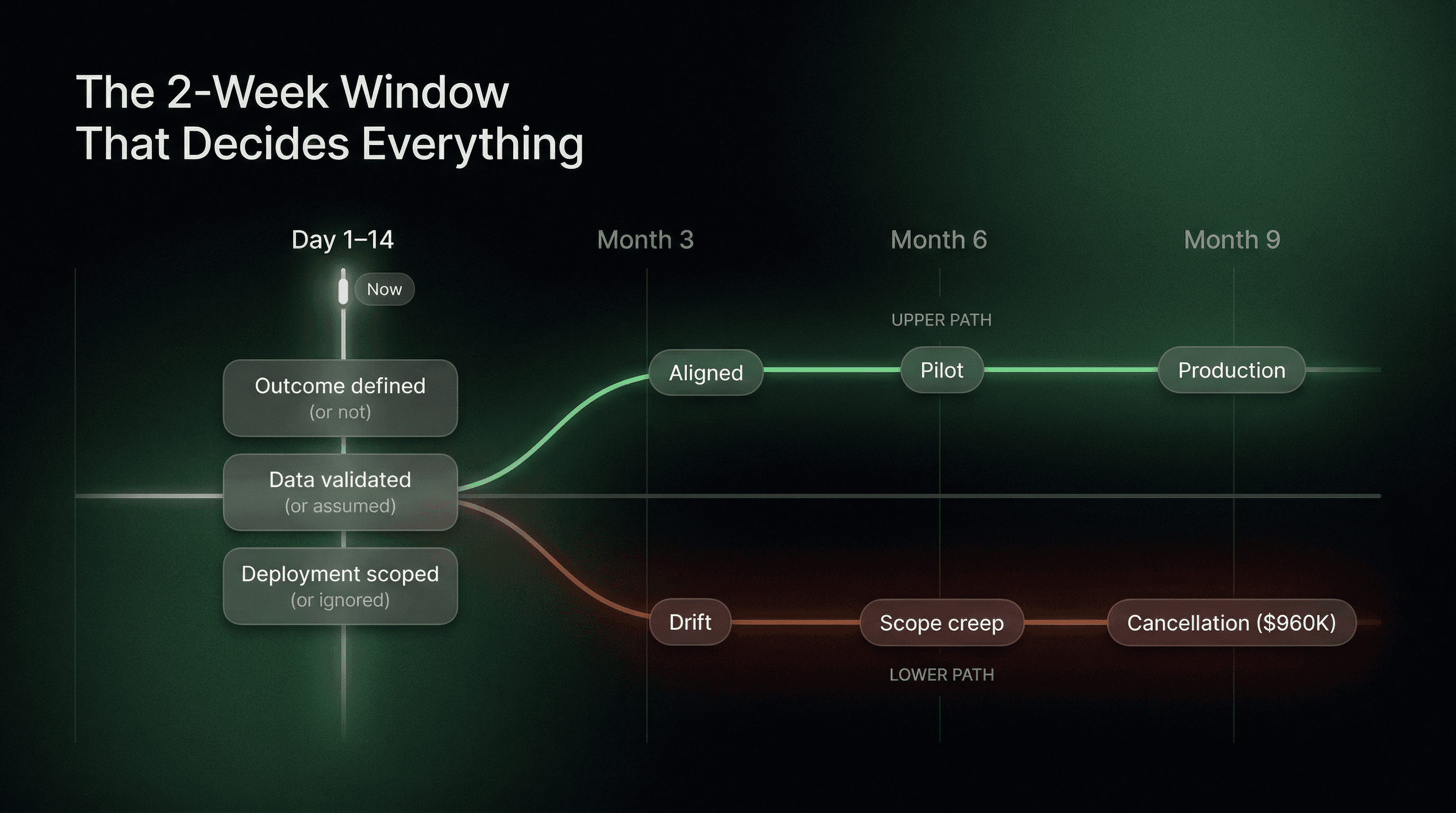
Decision 1: Outcome as a Number, Not a Direction
"We want to use AI to improve our support workflow" enters a project brief and never leaves. It sounds like a clear goal.
It is not a goal. It is a direction, and in a build environment, direction without a number means every decision is a negotiation. Should the model prioritise speed or accuracy? Should the system handle edge cases or route them to a human? How do you know when you are done?
Without a number, these questions are answered differently by the engineer, the product owner, the client stakeholder, and the executive who approved the budget. Each of them is optimising for something slightly different. The divergence is invisible in the first two months and catastrophic by month four.
The projects that ship define success as a number before the first sprint:
Not reduce support load: reduce first-response time from four hours to twenty minutes.
Not improve threat detection: reduce mean time to identify from seven hours to under thirty minutes.
Not automate the process: eliminate fourteen hours of manual data reconciliation per week.
Not improve customer onboarding: increase trial-to-paid conversion from 18% to 26% within the first thirty days of an AI-guided onboarding flow.
The number is the brief. The number does not change. Every technical decision in the build is evaluated against it. When Deloitte found that companies starting AI with a single, focused deployment are 2.5x more likely to scale to production, this is the mechanism behind that finding. Narrow scope forces a number. A number forces discipline. Discipline is what ships.
Decision 2: Data Readiness Validated, Not Assumed
Every client has clean data in the presentation. Almost no client has clean data in the production environment. This is not a criticism. It is a structural reality. The data used to demonstrate an AI use case to stakeholders is almost always a curated export, the best version of what exists. The data in the live system, integrated with legacy infrastructure, accessed through real APIs, with real latency and real inconsistencies, is a different thing entirely. The projects that fail discover this in month three. The projects that ship discover this in week one. Data readiness validation in week one does not mean a full audit. It means asking five specific questions about the actual production data environment before architecture is designed:
Where does the data live right now, and who owns access to it?
What is the format, and does it match what the model will need to ingest?
What is the update frequency, and does that frequency match the system's operational requirements?
What are the known gaps, and are they gaps the system can route around or gaps that break the use case entirely?
What is the integration path from the data source to the deployment environment, and has it been tested?
Projects that cannot answer these questions in week one will answer them in month three. The difference is that month three is after the timeline, the budget confidence, and the stakeholder trust have all been built on assumptions that are about to collapse. IBM's finding that only 26% of AI projects are successfully deployed at scale is, in large part, a data readiness finding dressed up as a technology finding.
Decision 3: Deployment Environment Scoped Before the Model
Most enterprise AI systems break in production at one of four specific points. None of them are in the model itself. All of them were knowable in week one.
Latency. A model that performs well in a test environment, with prepared inputs and no competing system load, frequently fails its own performance requirements under real production conditions. Enterprise systems carry concurrent user loads, background processing demands, and integration calls that test environments never replicate. A latency requirement that was never formally defined in scoping becomes a production crisis in week two of go-live.
Compliance by jurisdiction. Enterprise businesses operating across Benelux, the Nordics, or any multi-country environment face data residency requirements, GDPR obligations, and sector-specific regulations (particularly in fintech and healthcare) that vary by country. An AI system built without the compliance architecture of its deployment countries embedded in the original design will require partial or full reconstruction when legal review catches it. This happens after the build, not before.
Legacy system integration. The systems an AI deployment must talk to were not built to talk to it. ERP platforms, fleet management systems, and CRM infrastructure built five to fifteen years ago have APIs, data formats, and authentication protocols that require explicit integration work. Projects that treat legacy integration as a deployment task rather than a design input discover in month three that the integration is not a week of work. It is a month of work that changes the architecture.
Edge case routing. Every production AI system receives inputs it was not trained on. A user asks the wrong question. A data record arrives in an unexpected format. An external API returns a null value. If the system does not have a defined behaviour for these moments built into its architecture, it fails silently or noisily at exactly the moment a real user is depending on it. Defining edge case routing is not a QA task. It is a scoping decision.
These four failure points share one characteristic: they are all invisible in a demo environment and immediately visible in a production environment. Scoping the deployment environment in week one is not infrastructure planning. It is the act of building toward a known target rather than discovering the target after the build is complete.

Why the Two-Week Window Is the Actual Variable
The research on AI project failure consistently points to root causes that feel broadly distributed across data quality, change management, unclear ROI, and vendor selection. These are real. They are also consequences of decisions that compound over months from a very specific starting point.
Bad data quality in month four was usually knowable in week one. Unclear ROI in month six was usually the result of outcome-as-direction in the brief. Infrastructure incompatibility in month eight was usually a deployment environment that was never scoped.
The two-week window matters because every failure mode in AI projects has an earlier version of itself that is solvable. The later version, the one that makes the headlines about failed AI projects and wasted budgets, is the same problem after six months of compounding.
The organisations that ship are not working with better technology, larger budgets, or more experienced teams in every case. They are working with a more disciplined two-week start. Three decisions made with precision before the build begins. Everything after that has a reference point.
Everything without that reference point is improvisation, and improvisation is what $960,000 cancelled AI projects are made of.
Frequently Asked Questions
At what point do most enterprise AI projects fail?
Most enterprise AI projects fail during the scoping phase, specifically in the first two weeks, not during the build or deployment. Three decisions made or skipped in that window set the trajectory of the entire project: whether success is defined as a measurable number, whether data readiness is validated in the actual production environment, and whether the deployment environment is scoped as a first constraint rather than a later problem.
Why do AI projects succeed in pilot but fail in production?
Pilots are optimised for demonstration in a controlled environment. Production systems have to survive real users, real data volume, real integration with legacy systems, and real edge cases that were never anticipated in the brief. The gap between these two environments is not a technology gap. It is a scoping gap. Projects that scope for production from day one close that gap before the build starts. Projects that scope for pilot have to retrofit a production architecture onto a system that was never designed for it.
What is the most common reason enterprise AI projects get cancelled?
The most common reason, based on consistent patterns across fintech, logistics, cybersecurity, and enterprise operations, is that no measurable outcome was defined before the build started. When success is a direction rather than a number, the project drifts, each sprint delivering something technically correct that moves slightly further from what the business actually needed. By the time this becomes visible, the budget is spent and the stakeholder confidence is gone. McKinsey puts the average cost of cancellation at $960,000, but the cause traces back to a two-sentence brief that should have been a number.
How long does a well-scoped enterprise AI project take to reach production?
A focused, correctly scoped AI deployment takes between six and twelve weeks from outcome definition to production go-live. The primary variable is data readiness. Organisations with validated, accessible data in the production environment move faster. Organisations that discover data problems after architecture has been designed add two to four months. The timeline is almost always predictable in week one if the right questions are asked.
What is the difference between a production-ready AI system and a demo?
A demo is built to perform correctly in a controlled environment with prepared inputs. A production-ready system performs correctly in the deployment environment with real users, unexpected inputs, real data volumes, and real integration requirements, every day, not just during evaluation. Production-ready is not a technical standard. It is an operational standard: the system survives the environment it is deployed into, including its latency requirements, compliance constraints, legacy integrations, and edge cases.
What breaks most often when an AI system goes from demo to production?
The four most consistent failure points are latency under real system load, compliance requirements that vary by jurisdiction, legacy system integration depth, and edge case routing that was never defined in scoping. All four are invisible in a demo environment and immediately visible in production. All four are knowable and solvable in week one of scoping if the deployment environment is treated as a design input rather than a deployment task.
The decisions that determine whether your AI project ships or stalls are made in the first two weeks, not the last two. The patterns above hold consistently across industries and project types.
Sources
• MIT Project NANDA, The GenAI Divide: State of AI in Business 2025, July 2025 — via Fortune:
https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/
• Gartner: 85% of AI projects fail to reach production — via Dynatrace:
https://www.dynatrace.com/news/blog/why-ai-projects-fail/
• McKinsey: Failed AI project costs and ROI gap analysis — via Pertama Partners:
https://www.pertamapartners.com/insights/ai-project-failure-statistics-2026
• IBM: Why most enterprise AI projects stall before they scale, April 2026 — direct IBM source:
https://www.ibm.com/think/insights/why-most-enterprise-ai-projects-stall-before-scale
• Deloitte AI Institute: Single-focus deployment and 2.5x scale rate — via AGT strategy research
• RAND Corporation: 80% of AI projects fail, twice the rate of non-AI IT projects — via Yahoo Finance:
https://finance.yahoo.com/news/research-shows-more-80-ai-12330650 2.html
• Accenture: Reinventing Enterprise Operations with Gen AI, 2024 — direct Accenture source:
https://www.accenture.com/us-en/insights/strategic-managed-services/reinvent-operations-with-genai
• Gartner: 60% of AI projects lacking AI-ready data will be abandoned through 2026 — via SR Analytics:
https://sranalytics.io/blog/why-95-of-ai-projects-fail/